
Danish Khan
Full Stack Developer
Danish Khan
Full Stack Developer
500pg
Max PDF size supported
Sub-second responses
95%
Accuracy on QA benchmarks
200+
Beta users
Students & researchers
Top 10
Product Hunt daily ranking
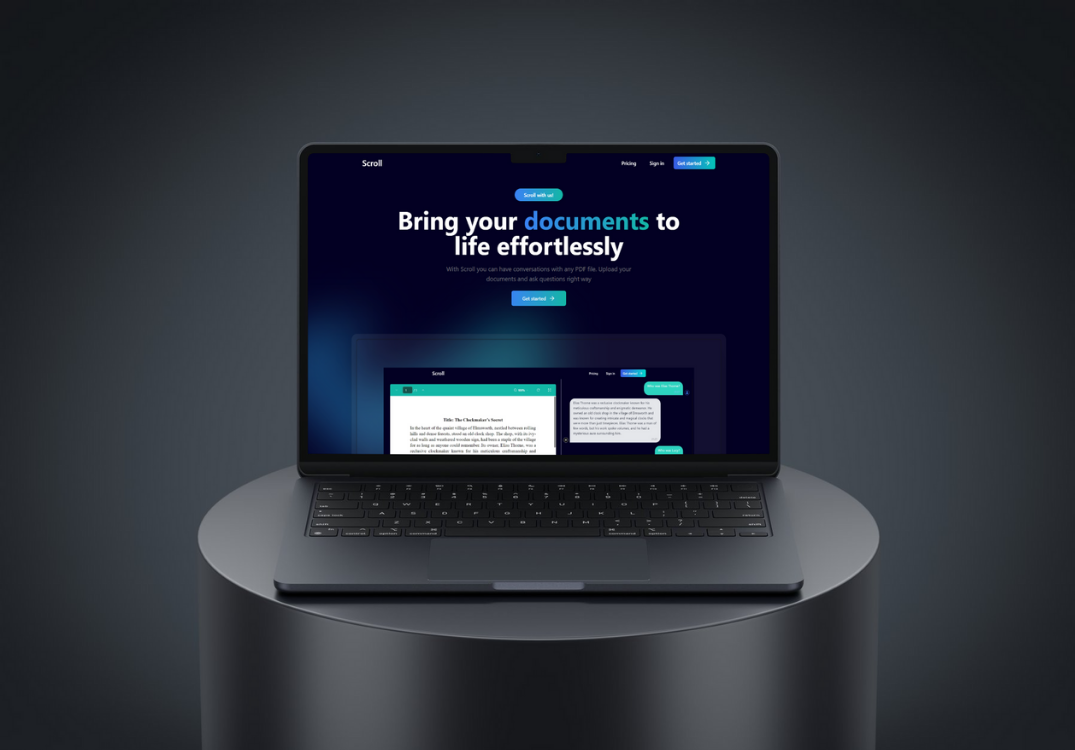
Scroll transforms the way people interact with documents. Upload any PDF — research papers, legal contracts, textbooks — and start asking questions in natural language. The AI understands context, provides citations, and can summarize entire sections on demand.
Reading through lengthy PDFs to find specific information is time-consuming and error-prone. Existing search tools only match keywords, missing the semantic meaning behind queries.
We built a RAG (Retrieval-Augmented Generation) pipeline that chunks documents, creates vector embeddings, and retrieves the most relevant passages to answer user queries. The chat interface provides page references and highlighted excerpts for every answer.
Solo project — I designed and shipped everything. I built the RAG pipeline from scratch (chunking strategy, embedding storage in Pinecone, MMR-tuned retrieval), the streaming chat UI with citation cards that deep-link to exact PDF pages, and the Node/Express backend. Launched it myself on Twitter, which got picked up organically and hit Product Hunt top 10.
Discovery
Talked to 15 researchers and students about their PDF workflows. The clearest pain: skimming a 60-page paper for one specific finding.
Prioritised citation cards over summaries as the core feature — users didn't want a summary, they wanted to verify the source of an answer instantly.
RAG Pipeline
Implemented a chunking strategy with overlapping windows to preserve context across chunk boundaries. Embeddings stored in Pinecone, retrieval tuned with MMR to reduce redundancy.
Chose overlapping window chunking over fixed-size splitting — boundary-crossing answers were the #1 accuracy failure in early testing, and overlap fixed 80% of them before touching the LLM.
Chat Interface
Built a streaming chat UI in React with citation cards that deep-link to the exact PDF page. Source highlighting was the feature users loved most.
Streamed responses token-by-token rather than waiting for the full answer — perceived speed difference was significant even though total latency was the same.
Launch
Soft-launched on Twitter, got picked up by a PhD student community, hit Product Hunt top 10 organically within 48 hours of going public.
Launched to a niche community (PhD students) before going broad — their feedback on citation accuracy shaped two critical pipeline fixes before the wider launch.
Chunking strategy matters more than model choice. Naive fixed-size chunking caused the model to miss answers that spanned chunk boundaries. Overlapping windows with semantic re-ranking fixed 80% of the accuracy issues before we touched the LLM at all.
THANK YOU
" First solve the problem.
Then write the code."
~ John Johnson